Operating Model, Delivery Governance & Controls
NSTACK Engagement Framework
Architects and senior engineers steer the system. AI agents handle the repetitive busywork. Every decision, quality gate, and architectural choice remains in human hands.
- Proposal Deck Template
- Responses to RFI
- Link to SOW
- Link to MSA
- Link to Figma Component Library
- Data Room (Invite only)
Outcome based: NSTACK will deliver the outcome aligned to a set of defined and thoroughly guard-railed and deeply analyzed outcome-based milestones. Final scope will be fully defined post "Foundation" discovery phase (Prototyping + Product Definition).
Core Principle
We are accountable for delivering outcomes and incremental business value. Human architects own every critical decision; AI agents accelerate execution under their direction.
How It Works
- Milestones tied to tangible deliverables and business value
- Acceptance criteria agreed upfront
- Flexibility in how we deliver, discipline in what we deliver
Cross-functional Team
- Product and solution leadership (Product Manager / TPA, Solution Architect)
- Design (UX/UI, experience strategy)
- Engineering (Frontend, Backend, AI/Platform)
- QA and automation
- Program/Delivery management
Key Characteristics
- Dedicated, not fractional
- Empowered decision-making: architects and leads own the "what" and "why," agents handle the "how"
- Designed to scale as scope expands
- Human engineers focus on architecture, design reviews, and stakeholder alignment while agents execute boilerplate, testing, and documentation
Our agent training is enforced by the SpecRun, using self-contained micro text models instead of generalized agents. Each agent operates within a strict, predefined contract, ensuring outputs are context-driven, deterministic, and non-hallucinatory. Agents can only produce outcomes that are directly supported by the context they are given.
AI Agent Blueprints
Each agent is defined by a clear specification:
- Purpose: Single responsibility and explicit task scope
- Context Contract: Approved, versioned inputs treated as the source of truth
- Input / Output Schema: Structured, predictable formats
- Constraints: Explicit "can / cannot" boundaries
If required context is missing, the agent must ask for clarification, escalate, or return an "insufficient context" response. It never guesses. Human practitioners always remain in the loop to validate, approve, and steer agent output.
Pre-training
Foundation models are constrained and aligned to the task type before domain use.
Data Set (Domain Knowledge Capital, Skills, Tools)
- Client-approved domain knowledge
- Task-specific skills and rules
- Explicit tool access and limitations
Explicit Operating Boundaries
Each agent is governed by a strict SpecRun contract that defines:
- What the agent is allowed to do (approved tasks only)
- What the agent is explicitly not allowed to do
- Which data sources and tools it can access
- Which outputs it is permitted to generate (template-based response generation)
Anything outside this boundary is treated as out of scope.
Context-Limited Reasoning
- Agents can reason only over the context provided at execution time
- No external knowledge, inference, or "best practice guessing" is allowed
- Expert-in-the-Loop: If context is incomplete or ambiguous, the agent must return an insufficient context response, or escalate to a human
- ISO 27001
- SOC2 (Transitional SOC compliance)
- Toolset: AWS, Miro, Github, Notion, Figma, Terraform, N8N, Cursor, Docker
- NSTACK.AI Toolset: Google Suite (chat, meetings, email)
Tools and Access
A Secure, Integrated, and Transparent Delivery Ecosystem
We operate with a standardized toolchain that enables seamless collaboration between client teams, delivery teams, and AI agents.
- Single source of truth for requirements, designs, and delivery artifacts (Notion, Miro, Figma, Github, AWS)
- Least-privilege access aligned to roles and data sensitivity
- Client visibility by default, not by exception
Productivity Environment
Engineered for Outcome Acceleration, Not Just Efficiency
Our productivity environment is purpose-built to increase throughput while improving quality, using a humans + agents model.
- Automated CI/CD, testing, and quality gates
- Reusable design systems, components, and reference architectures
- AI-assisted development, QA, and validation within defined guardrails
Differentiation: AI is used to compress cycle time, not replace accountability. Architects and senior developers retain ownership of decisions, quality, and outcomes. Agents handle the repetitive work: scaffolding, test generation, documentation, and deployment scripts. The humans steer; the agents execute.
Delivery Rhythm & Governance
Continuous validation, fast feedback, and informed decision-making without slowing delivery.
Delivery Cadence:
- Time-boxed iterations with clearly defined goals (Phased Approach)
- Regular demos and working sessions with stakeholders
- Continuous backlog refinement aligned to milestone outcomes
Validation and Quality Gates:
- Explicit acceptance criteria
- Automated and human quality checks
- AI-assisted validation where appropriate, within guardrails
Next Steps after SOW Signature
- Soft kick-off workshop
- In person workshop
Our go-to-market approach is centered on delivering incremental, high-value business outcomes by transforming one piece of a client's roadmap at a time. We deploy seasoned practitioners and leaders who specialize in high-value consulting and the delivery of AI-driven solutions. This engagement model is designed to be organic and intertwined, moving seamlessly from strategic ideation to tangible product delivery.
We initiate engagements with short, collaborative workshops to identify immediate business challenges and opportunities, ensuring that every effort is tied to a measurable success outcome. This initial phase rapidly transitions into building and validating solutions through a continuous, hypothesis-driven process. Our approach filters out noise and focuses on decision-grade signals from customer, market, and operational data, ensuring that product choices are always informed and validated.
Our agentic engineering centers serve as a force multiplier, leveraging a suite of accelerators and AI-powered engineering tools to deliver these bite-sized outcomes with exceptional speed and precision. Architects define the blueprints; agents execute the build. Human engineers focus on the hard problems: system design, integration strategy, and stakeholder alignment. The busywork is automated away. Every change is traceable to a specific decision and signal, with governance and compliance embedded throughout the process. This allows us to scale action safely, delivering a continuous stream of value that evolves with our clients' needs, from initial prototypes and MVPs to full-scale system transformations and new feature rollouts.
The diagram below illustrates the full platform architecture spanning five operational planes: Network/Security, Developer, Application, Delivery, and Control/Ops. Each plane is purpose-built for the roles that operate within it and enforces strict boundaries between concerns.
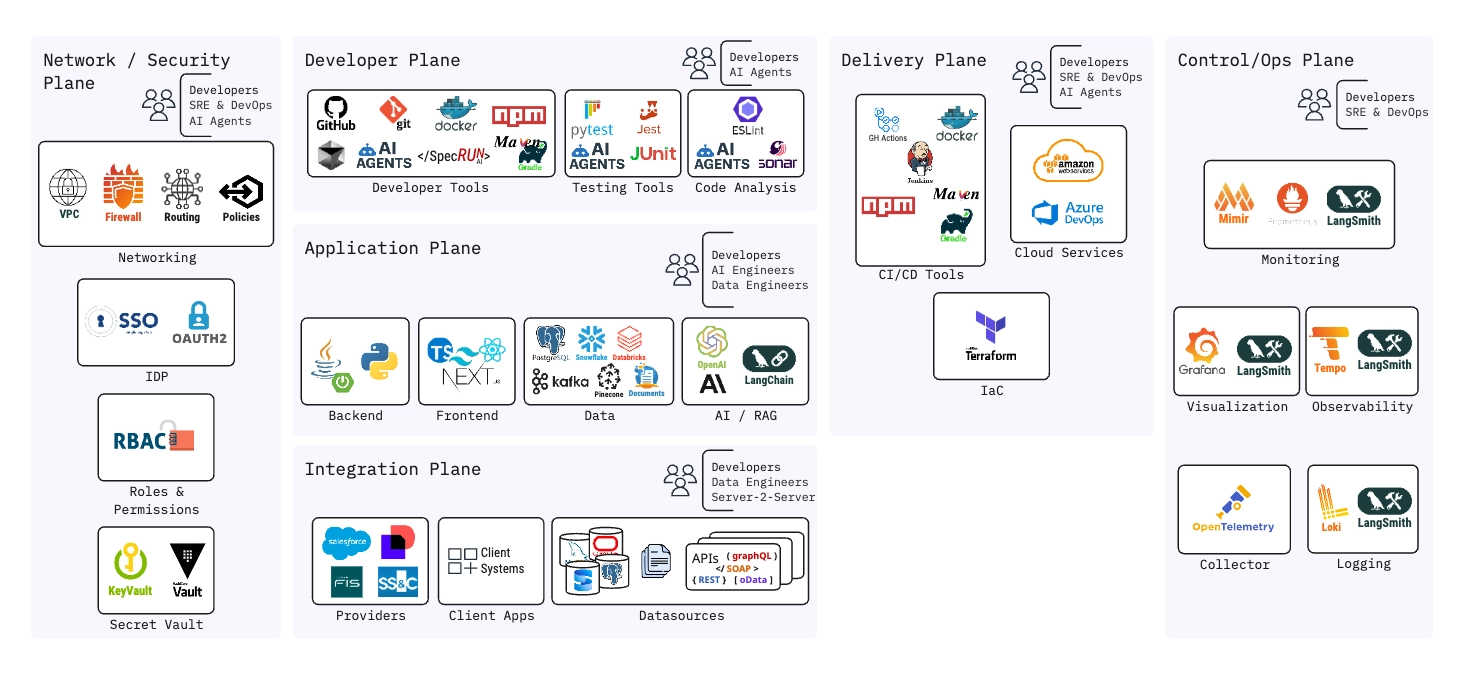
NSTACK Platform Architecture - Operational Planes Overview
| Question | Answer |
|---|---|
| How do you ensure "outcome-based" doesn't turn into scope ambiguity? | Outcomes are defined with explicit acceptance criteria and measurable signals. While we maintain flexibility in how outcomes are achieved, the what is contractually clear. Any change to outcomes follows a controlled impact assessment covering timeline, cost, and risk. |
| What happens if requirements evolve mid-engagement? | We expect requirements to evolve. Our model accommodates this through backlog reprioritization within agreed milestones. If evolution impacts committed outcomes, we make tradeoffs explicit and decision-driven rather than absorbing hidden risk. |
| How do you prevent AI agents from hallucinating or producing incorrect outputs? | Agents operate within strict SpecRun contracts and self-contained micro text models. They can only reason over approved context. If context is missing or ambiguous, the agent is required to fail safely, asking for clarification or escalating to a human instead of guessing. |
| Can agents learn or adapt on their own over time? | No. Agents do not self-train or evolve autonomously. All changes to agent behavior are intentional, versioned, and governed. This prevents drift, unexpected behavior, and compliance risk. |
| What role do humans play once agents are in place? | Humans retain ownership of decisions, quality, and outcomes. Agents accelerate execution, reduce cognitive load, and improve consistency, but they do not replace accountability or judgment. |
| Is client data ever used to train shared or external models? | No. Client data is only used within explicitly approved contexts and never for training shared models unless contractually authorized. Data usage, retention, and residency are defined upfront and enforced technically. |
| How do you ensure auditability of AI-driven decisions? | All agent executions are logged, including inputs, context, and outputs. SpecRun and micro models are versioned, making decisions traceable and auditable. |
| How do you ensure quality while moving quickly? | Speed comes from automation and reuse, not shortcuts. Quality is enforced through automated testing, validation agents, and human review at defined checkpoints. |
| How do you manage risk without slowing delivery? | Risk management is embedded into delivery cadence, not treated as a separate process. Risks are surfaced through frequent validation points, demos, and metrics. Governance is proportional to risk. |
| How do you scale the solution after initial delivery? | We design for scale from day one using modular architectures, reusable components, and clearly defined service boundaries. Scaling becomes additive, not disruptive. |
| Who is ultimately accountable if milestones are missed? | Accountability sits with a single, named program owner on our side. That owner has authority over scope tradeoffs, resourcing adjustments, and escalation, ensuring corrective action happens immediately. |
| Question | Answer |
|---|---|
| How do you build product? | We start by understanding how your operation actually works today, not just the workflows, but where judgment, interpretation, and repetition live. From that foundation, we identify which parts of the system benefit from human decision-making and which can be safely augmented with AI. We don't treat AI as a feature; we treat it as an accelerator for ingestion, comparison, validation, and insight generation. We design these AI capabilities in a way that your teams can understand, trust, and extend over time. |
| How do you prioritize? | We prioritize based on where value and risk intersect. First, we identify decisions that matter, the moments where speed, accuracy, or confidence materially change outcomes. Second, we isolate dependencies: what needs to exist before anything else can scale. Third, we intentionally deprioritize anything that increases surface area before foundations are stable. This approach ensures the MVP is not a demo, but something that can survive real operational use. |
| What experience do you have in retirement? | We've worked across the retirement ecosystem at different scales, supporting retirement products where accuracy, client trust, and operational reliability were non-negotiable. We've also operated at a very different scale: supporting retirement and fund-related platforms that serve hundreds of entities. That combination gives us a grounded perspective from single-provider depth to multi-client complexity. |
| How do you ensure you're hitting milestones and deadlines? | Our first six weeks are deliberately front-loaded with operational discovery and validation. This allows us to surface risks early, align on scope boundaries, and prevent rework later. From there, we work backwards from agreed outcomes, aligning design, engineering, and validation against a shared work back plan. |
| What makes your team unique compared to others? | Our teams bring together product leadership, technical depth, and domain experience, which allows us to make decisions in ambiguity without over-engineering. We're comfortable challenging assumptions early, because that's where the most value is created. Most importantly, we build platforms that are shaped around how organizations actually operate, not how diagrams suggest they should. |
| How do you ensure you really understand our product and domain? | In addition to operational immersion, we map where AI can safely augment existing processes versus where it should only assist. For example, extracting plan attributes is a good candidate for automation; resolving discrepancies or approving changes may not be. This distinction only comes from deeply understanding the domain, the risks, and the decision-making model you operate under. |
| Question | Answer |
|---|---|
| Who owns the canonical data model definition, and how is schema evolution governed? | The client owns the canonical data model. A headless CMS serves as the centralized, authoritative source for all data model and ontology definitions, fully owned and accessible by the client. Schema evolution is governed through configuration-based workflows rather than custom code changes. |
| How will ontology/taxonomy changes be managed as retirement products evolve? | The solution recommends a headless CMS to centralize data ontology definitions, paired with automated ingestion pipelines powered by configuration-based workflow technology. This enables a low-code, no-code approach where ontology and taxonomy changes propagate through the system by configuration, making the platform future-ready to scale without architectural overhauls. |
| How are data quality rules, validation thresholds, and reconciliation logic defined and versioned? | Data quality is treated as code, defined declaratively, version-controlled, and enforced automatically through a medallion architecture (bronze, silver, gold). All validation rules, transformation logic, and reconciliation policies are managed as configuration-based artifacts that follow the same Gitflow process. |
| How are data lineage and provenance tracked from ingestion through AI interpretation to reporting? | Every data point is traceable from source to insight, across every layer. The medallion architecture provides built-in lineage by design. On the AI interpretation layer, a domain-specific trained model enables a 'talk to your data' experience. Every AI-generated insight traces back to the gold layer, maintaining a clear link between what the data says and where it came from. |
| How do you isolate client data in a multi-tenant platform? | Tenant isolation is enforced end-to-end through a Data Lakehouse architecture, with flexible segregation strategies. Each tenant gets a dedicated lake within the Gold Layer, where data can be isolated either logically or physically depending on governance constraints and compliance requirements. |
| How is PII data managed? | PII is protected at every layer (at rest, in transit, and in use). All PII is encrypted using industry-standard protocols: AES-256 at rest, TLS 1.2+ in transit, and field-level encryption where required. AI agents never have access to raw PII data. PII protection is embedded in every layer of the architecture by design. |
| Does the platform need to ingest all the data to provide an effective data analysis system? | No. We recommend a 'minimum data footprint' approach, ingesting only what's strictly necessary to reduce compliance risk and PII exposure. If a provider's platform natively supports AI connectivity, data can be analyzed in place without ingestion. Less data ingested, less risk, same analytical power. |
| Is a reporting system to visualize the data part of the solution? | Yes, and we're going beyond traditional dashboards. The reporting and visualization layer is built on a Generative AI/UI model that dynamically renders data visualizations based on natural language queries. A pre-built reports layer will also be implemented, with an AI-assisted mechanism to build those reports. |
| Question | Answer |
|---|---|
| What happens if the client later chooses not to use SpecRun or your agentic tooling? | SpecRun is an accelerator, not a dependency. It's an Agentic Contextualization Framework that applies context and prompt engineering best practices. The client can stop using SpecRun at any point without affecting any previously generated artifacts, code, documentation, or workflows. There's no lock-in. |
| How is AI output validated, versioned, and auditable for SOC2 and client scrutiny? | SpecRun versions and logs every artifact it produces, giving you a clear trail of what was generated, when, and in what context. We have quality gates in place: static code analysis, code linters, and automated quality checks are all part of the pipeline. We follow a Gitflow methodology to ensure proper version control. |
| How is documentation kept continuously in sync with fast, AI-accelerated delivery? | Documentation never falls behind because it's part of the same loop that drives delivery. Our AI-SDLC maintains a single source of truth for all requirements. When something changes, the process reacts automatically. There's still a human in the loop at every step. |
| How do you prevent AI agents from introducing inconsistent patterns or architectural drift? | Architecture and product integrity are never delegated to AI, they're owned by people. The Architect and Product Manager are responsible for all architectural and product definitions. SpecRun implements a multi-agent quality framework where dedicated agents evaluate the output of other agents. |
| How do human and AI activities coexist within the SDLC lifecycle? | Humans define, govern, and approve. AI accelerates execution under their supervision. The Product Manager, Architect, and design team own all product, technical, and UI/UX definitions. AI agents consume those definitions to generate execution plans, code, documentation, and tests, but nothing moves forward without human validation. |
| How are AI agents constrained by scope, permissions, and context boundaries? | Every AI agent operates within clearly defined boundaries, scoped by role, context, and permissions. SpecRun implements role-based methodologies where each agent has a precise definition of what inputs it can consume and what context it has access to. The human in the loop normalizes and curates inputs before they reach any agent. |
| How do you ensure future client engineers can understand decisions made with AI assistance? | Decisions aren't made by AI, they're made by people. All key decisions are formally documented through ADRs (Architecture Decision Records) and RFCs (Request for Comments), capturing the context, rationale, alternatives considered, and final outcome. |
| How is "human ownership" enforced when agentic tools generate code or workflows? | Human ownership is enforced at every layer. Humans own all definitions and approve every agent-based execution plan before it moves forward. SpecRun's multi-agent quality framework, Gitflow version control, static analysis, and formal decision records ensure everything remains traceable and auditable. |
| Question | Answer |
|---|---|
| Which environments will the client have full access to versus read-only visibility? | We can adapt to either of two operating models: bring our own development ecosystem, or operate entirely within the client's existing ecosystem. Either way, the client retains full access and visibility across all layers: cloud infrastructure, source code repositories, CI/CD pipelines, monitoring dashboards, and all project documentation. There are no black boxes and no gated environments. |
| What standards govern code quality, security scanning, and architectural compliance? | Quality, security, and compliance are enforced consistently across every layer. Frontend: ESLint, Prettier, component-level testing, accessibility audits. Backend: Static code analysis, OWASP-aligned security scanning, API contract validation. Data: Schema validation at every medallion layer, PII classification. Infrastructure: IaC with policy-as-code enforcement, container scanning, Well-Architected Framework evaluation. |
| What productivity metrics do you track to ensure speed does not degrade quality? | We track Delivery Velocity (sprint throughput, cycle time, deployment frequency), Code Quality (coverage, static analysis scores, defect escape rate), AI-Specific Metrics (agent output acceptance rate, rework ratio), Data Quality (validation pass rates, reconciliation discrepancy rates), and Operational Health (deployment success rate, MTTR, incident frequency). If velocity metrics go up but quality metrics go down, we slow down and adjust. |